Под словом перевод в данной статье следует понимать так называеымый овервойс, т.е. голос переводчика (или озвучивающих фильм актёров), накладываемый на звуковую дорожку фильма поверх голосов актёров, озвучивающих фильм на языке оригинала.
Этот вопрос постоянно задаётся в различных форумах, и, как правило, на него везде дают совершенно одинаковый ответ: никак. На первый взгляд это утверждение вполне логично: если оригинальный звук уже смешан с переводом, то извлечь его обратно, по логике вещей, не легче, чем, например, отделить сахар от воды, если он уже насыпан в стакан.
Но не всё так безнадёжно. Осмелюсь утверждать, что в ряде случаев выделить перевод из смикшированной звуковой дорожки можно (но не всегда!), о чём и пойдёт речь в этой статье.
Что вам нужно для этого (что нужно для продолжения чтения этой статьи)?
-
Обладать базовыми знаниями в области цифровой обработки сигналов;
-
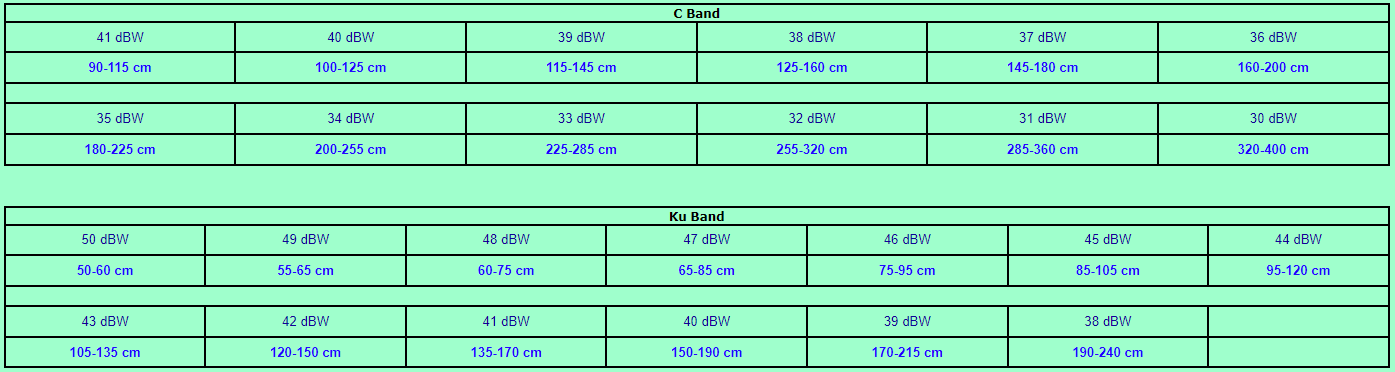
Уметь пользоваться каким-либо из достаточно развитых пакетов для обработки звука CoolEdit, Sound Forge, WaveLab и т.п. В этой статье все примеры и иллюстрации приведены с использованием WaveLab. Если вы используете другой пакет, вам придётся подбирать аналогичные операции и фильтры в том пакете, которым пользуетесь вы);
-
Отдавать себе отчёт в том, что чудес не бывает, и конечный результат никто не гарантирует, а его качество будет напрямую зависеть не от аккуратного выполнения приведённых инструкций, а в основном от творческого подхода, умения мыслить и применять новые техники для его достижения.
Иными словами, основная идея этой статьи полностью изложена в разделе под номером 1, а все остальные разделы всего лишь иллюстрируют, как эту идею можно использовать на практике.
1. Общий принцип
На самом деле звуковая дорожка с наложенным переводом представляет собой не более чем смесь двух сигналов: оригинального звука и голоса переводчика (обозначим её как S+V). Если у вас к имеется оригинальная звуковая дорожка без наложенного перевода (то есть просто S), то извлечение чистого голоса переводчика – представляет из себя задачу для первого класса:
V=(S+V) – S.
То есть нам нужно просто вычесть из одного сигнала другой. Если вы имеете представление о цифровой обработке сигналов, то вы должны знать, что это делается суммированием двух сигналов, фаза одного из которых инвертирована.
Реальность же, однако, такова, что для того, чтобы эта арифметика начала работать, сигналы S в звуковой дорожке с переводом и в звуковой дорожке без перевода должны совпадать посэмплово. Это резко ограничивает круг материала, подходящего для нашей задачи.
Во-первых, отпадают случаи, когда имеется оригинальный звук без перевода, снятый с DVD, и звук с переводом, снятый с другого источника (видеокассета, Video-CD, телеэфир и т.п.). Даже если вам удастся более или менее синхронизировать эти две дорожки, синхронизировать их посэмплово (т.е. с точностью до байта) вряд ли представляется возможным.
Во-вторых, отпадают случаи, когда имеется две звуковых дорожки (со звуком и без звука), различающиеся по спектральным характеристикам (такое часто бывает, например, при преобразовании 6-канального звука с DVD).
3. В меню Audio выбираем AVI Audio;
4. В меню Audio выбираем Full Processing Mode;
5. В меню Audio выбираем Conversion и настраиваем параметры вот так:
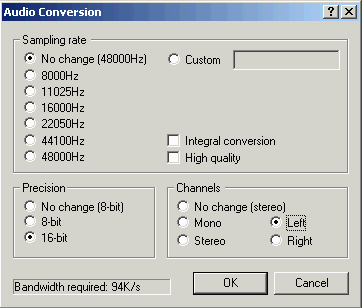
7. Делаем второй проход:
 <!–IMG2–>
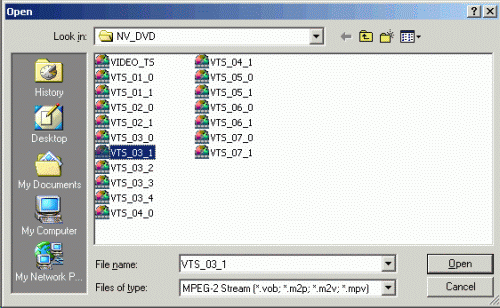
<!–IMG2–>В меню File выбирайте Open и выделите оба наших файла, удерживая Shift или Ctrl:
 <!–IMG3–>
<!–IMG3–>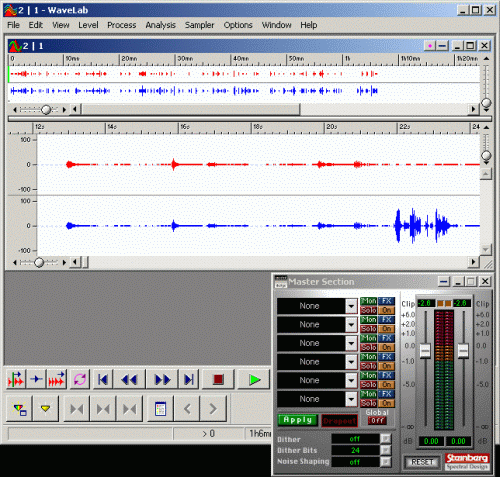 <!–IMG4–>
<!–IMG4–>-
Первый слот оставьте пустым (я потом объясню, зачем);
-
Во второй слот выбираем фазоинвертор. Смысл этой операции – инвертировать фазу одного из каналов. Фильтров, выполняющих эту задачу, навалом, причём ввиду простоты реализации операции она входит во многие более сложные фильтры как одна из операций. Я для этого использую, например, VST-фильтр Flipper. Простой, бесплатный и со своей задачей справляется.
 <!–IMG5–>
<!–IMG5–>3. В третий слот выбираем Leveller (из встроенного набора фильтров WaveLab).
 <!–IMG6–>
<!–IMG6–>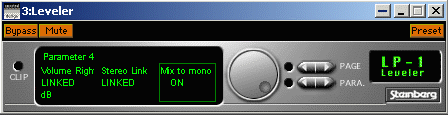 <!–IMG7–>
<!–IMG7–>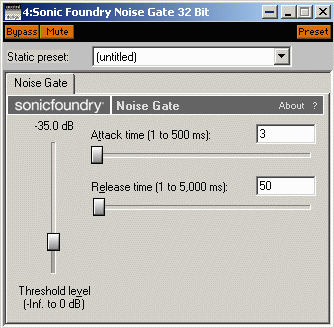 <!–IMG8–>
<!–IMG8–> <!–IMG9–>
<!–IMG9–> <!–IMG10–>
<!–IMG10–>Каналы имеют различные уровни громкости;
Каналы имеют различные спектральные характеристики;
Каналы имеют в своём составе различные сигналы;
Каким образом каналы могут быть смещены друг относительно друга? Это хорошо видно на следующей иллюстрации:
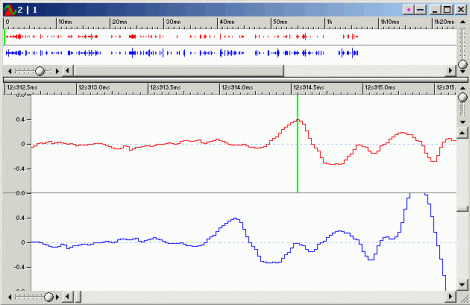 <!–IMG11–>
<!–IMG11–>Далее, каналы могут иметь различные уровни громкости:
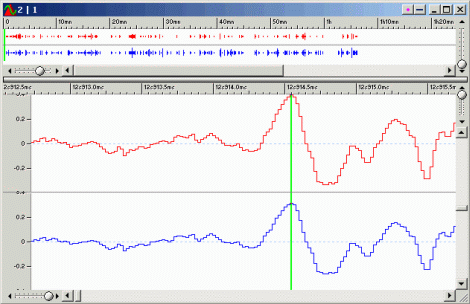 <!–IMG12–>
<!–IMG12–>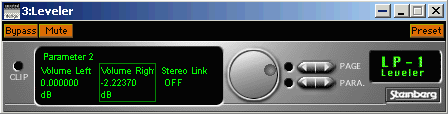 <!–IMG13–>
<!–IMG13–>Далее, если каналы имеют различные спектральные характеристики, можно попробовать отфильтровать оба канала перед их обработкой, выделив только тот диапазон частот, который нас интересует, а именно – диапазон голоса переводчика. Для этого в первый слот (помните, мы оставили его пустым?), выберем любой графический эквалайзер (я, например, использую для этого DirectX эквалайзер от Sonic Foundry), и настроим его на средние частоты, примерно от 300 до 1500 кГц:
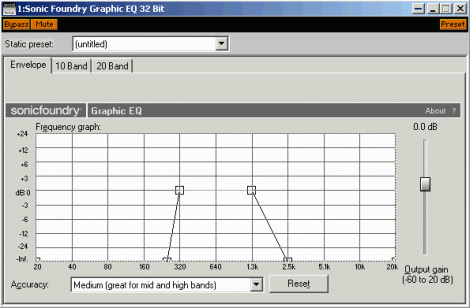 <!–IMG14–>
<!–IMG14–>2. Диски, на которых нет оригинальной и/или русской звуковой дорожки;
3. Диски, на которых оригинальная и/или русская дорожка записана в формате DTS
(в этой статье рассматриваются только звуковые потоки AC3).
 <!–IMG15–>
<!–IMG15–>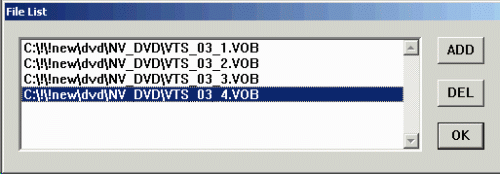 <!–IMG16–>
<!–IMG16–>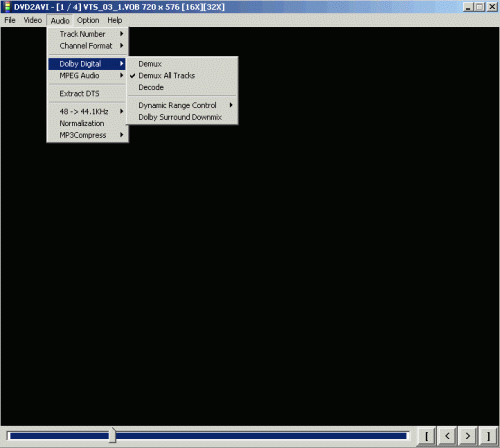 <!–IMG17–>
<!–IMG17–>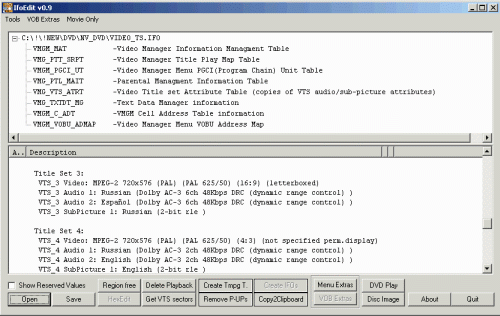 <!–IMG18–>
<!–IMG18–>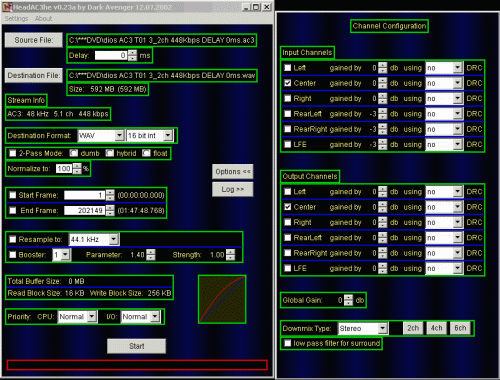 <!–IMG19–>
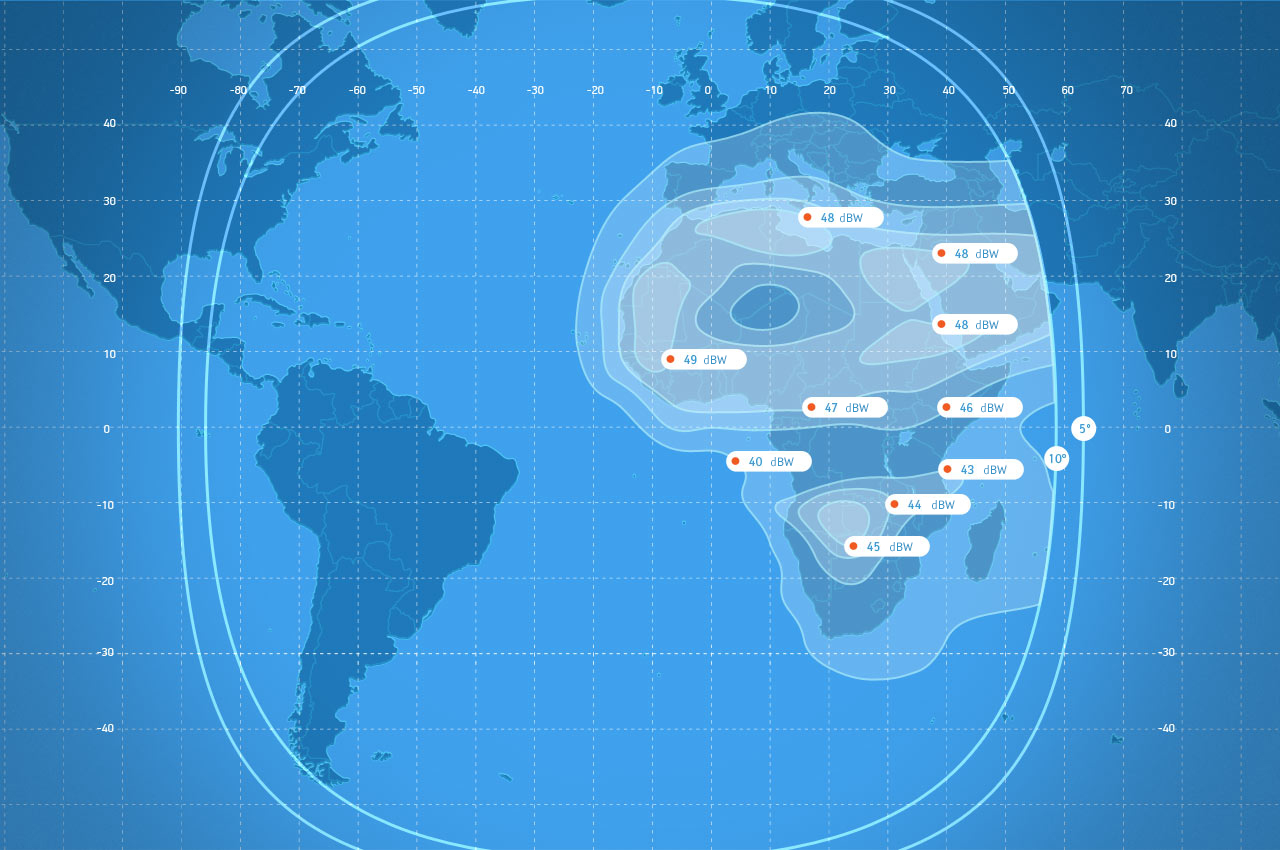
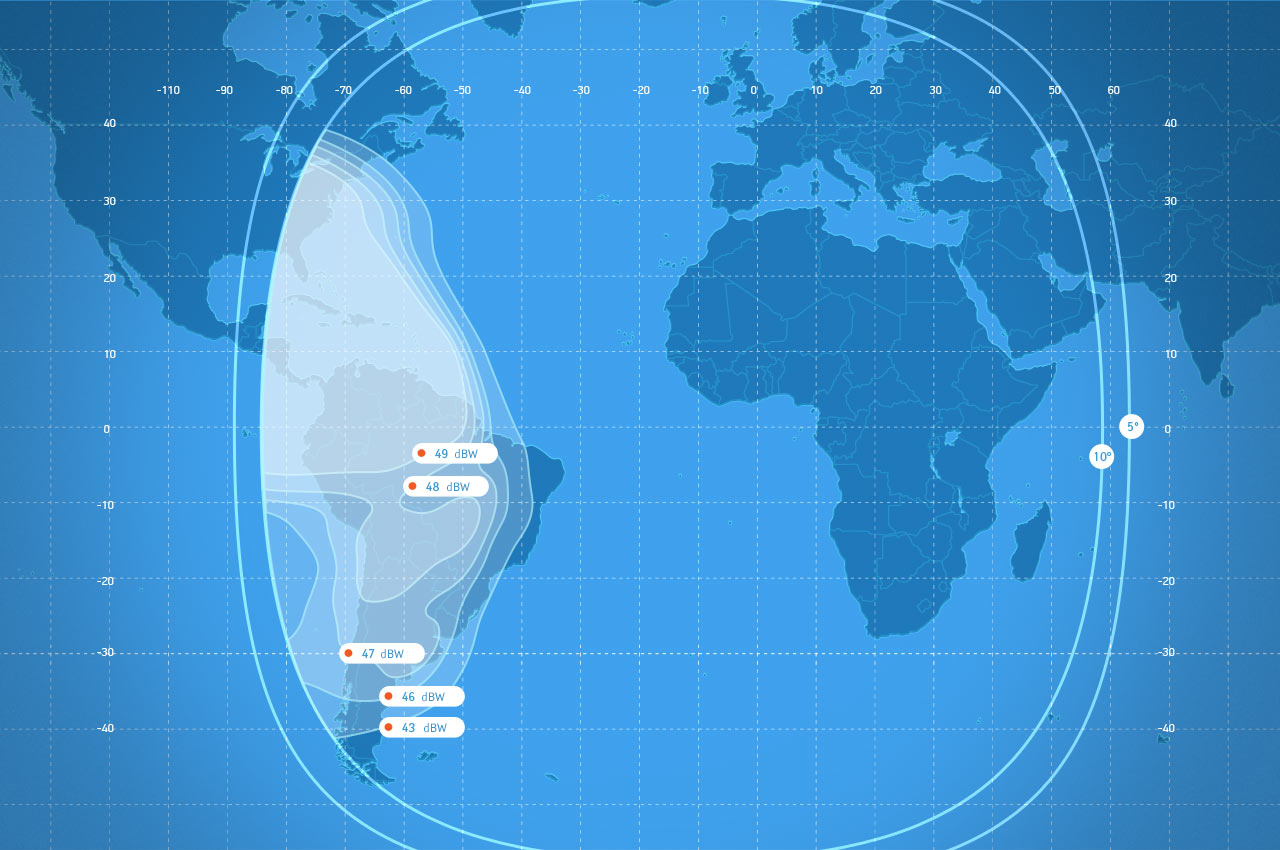
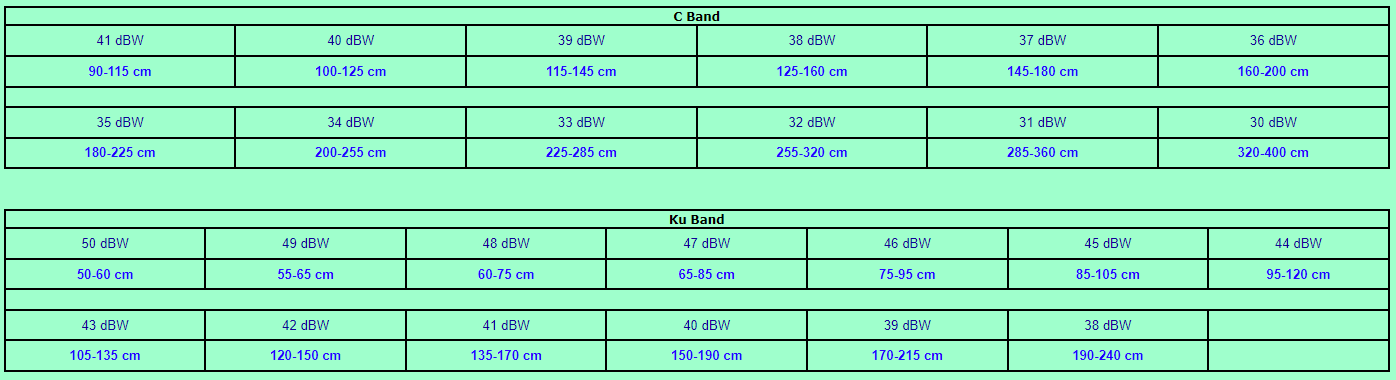
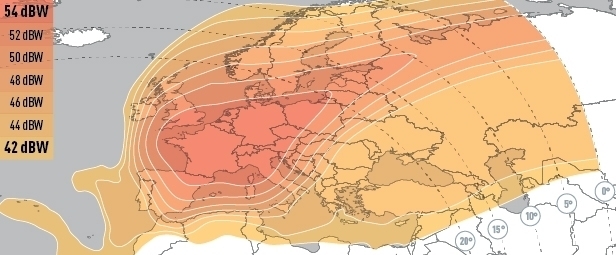
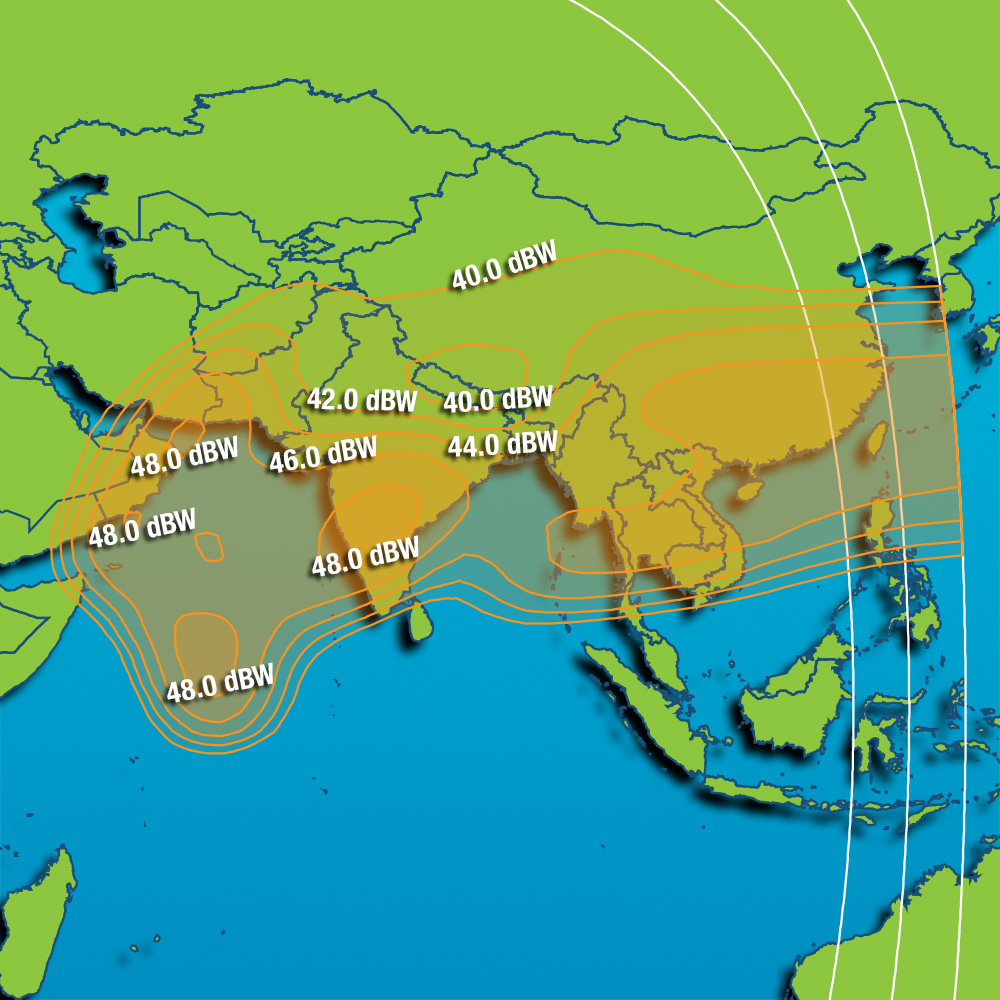
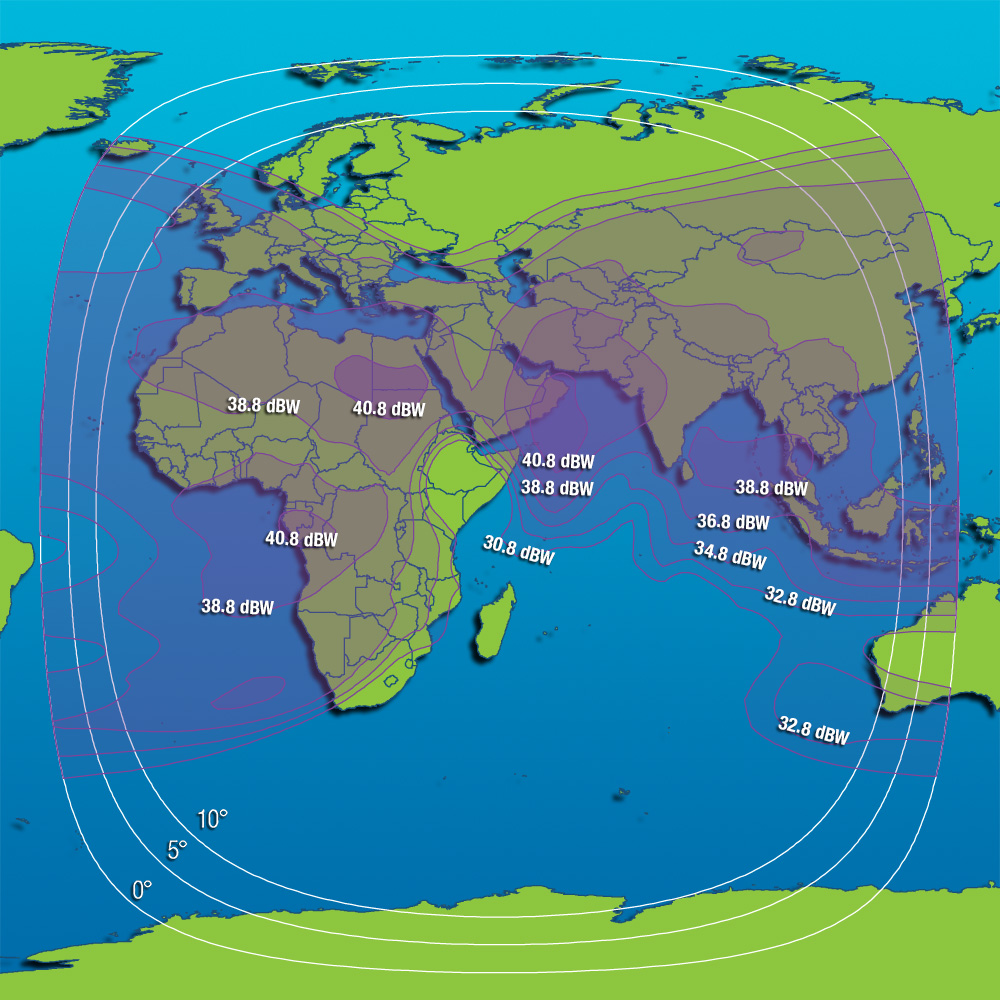
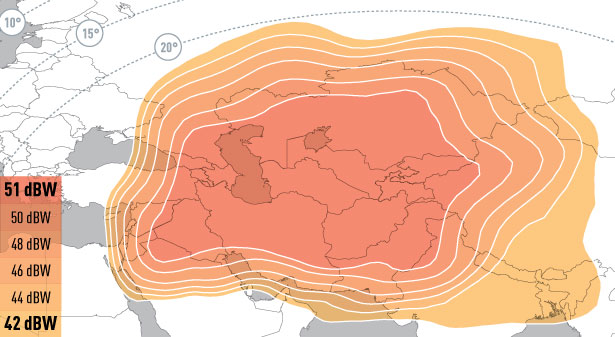
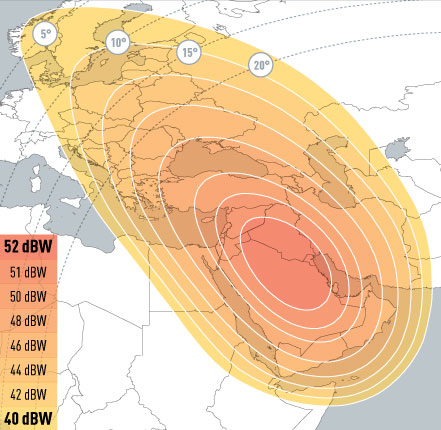
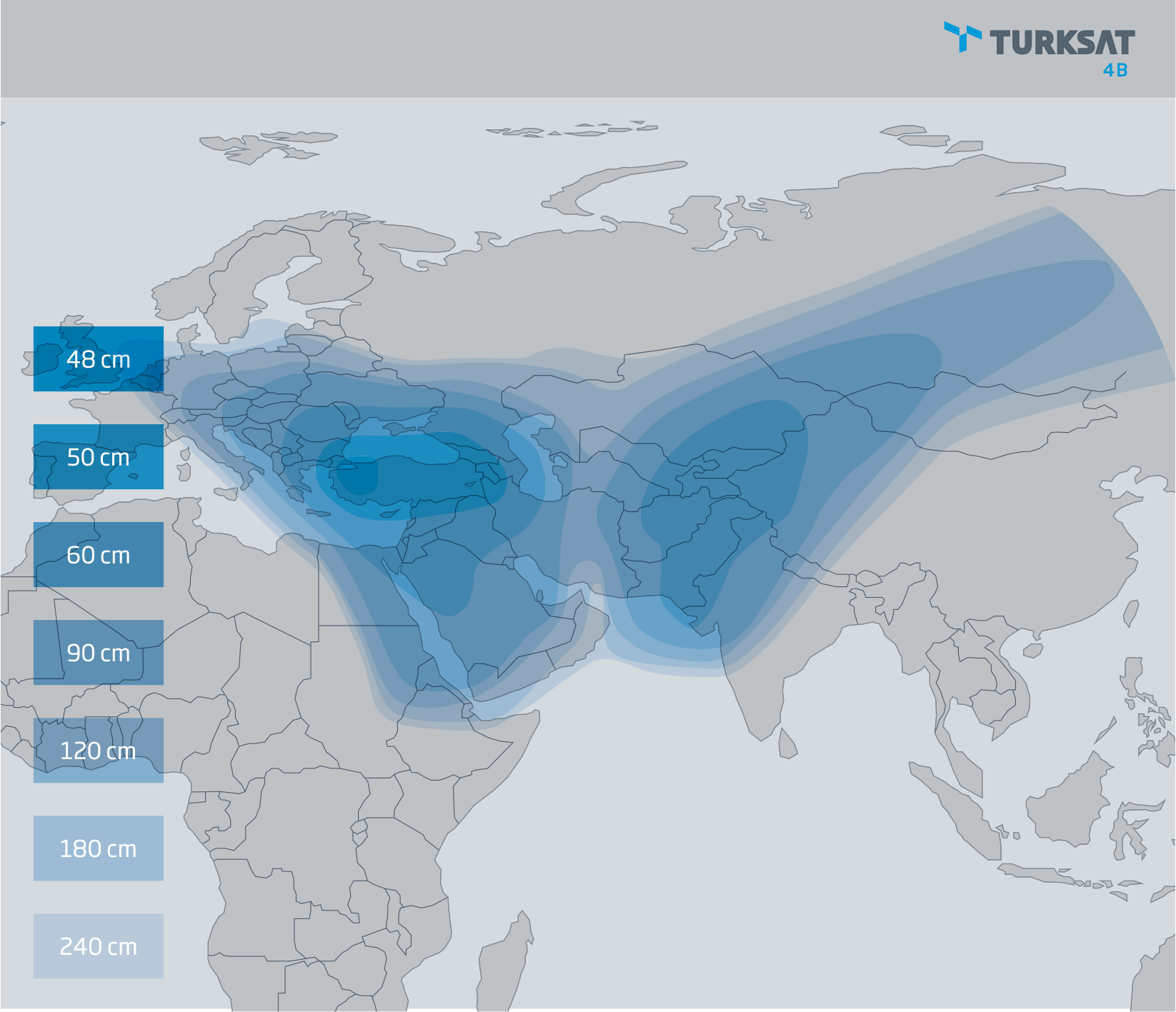
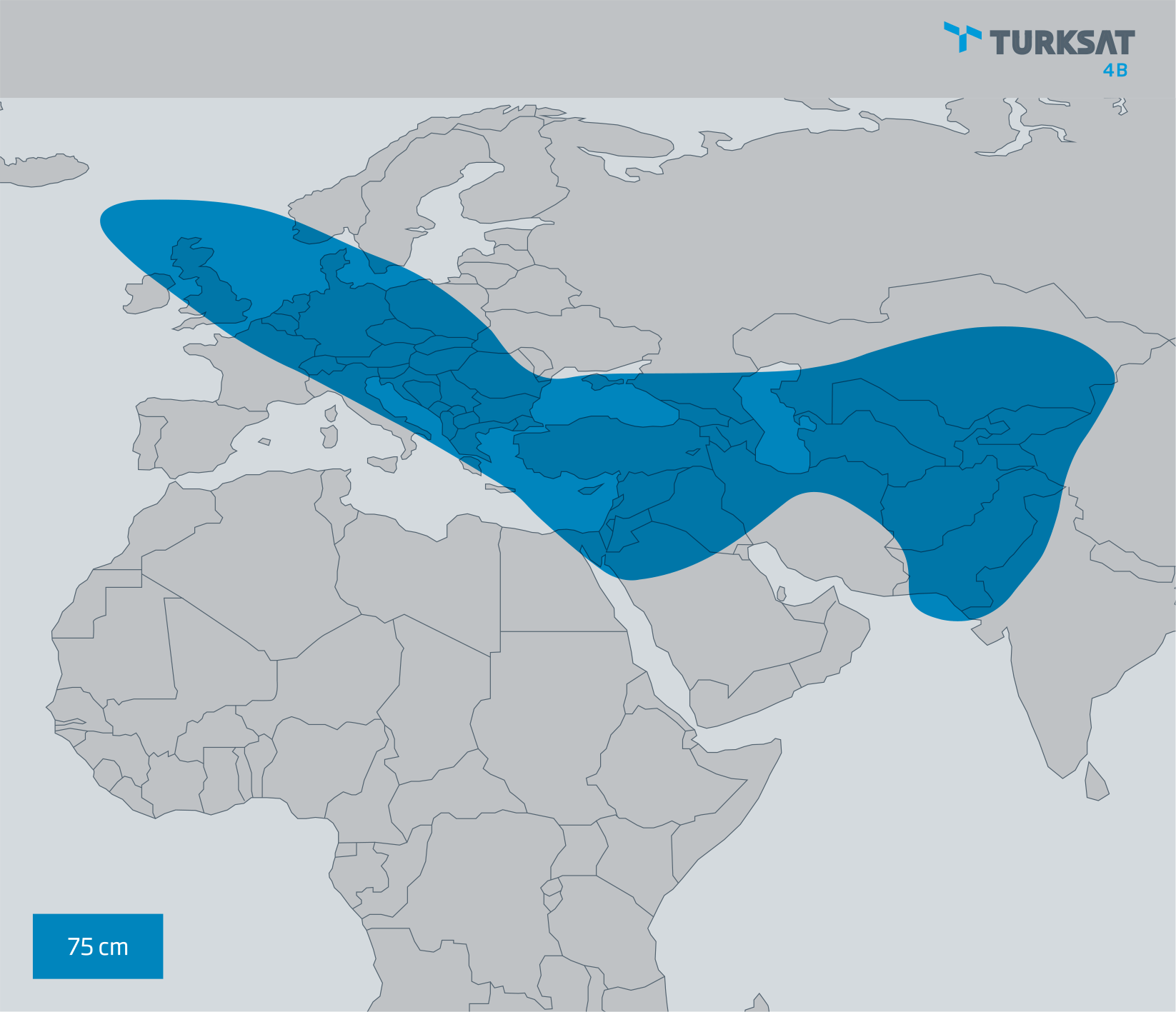
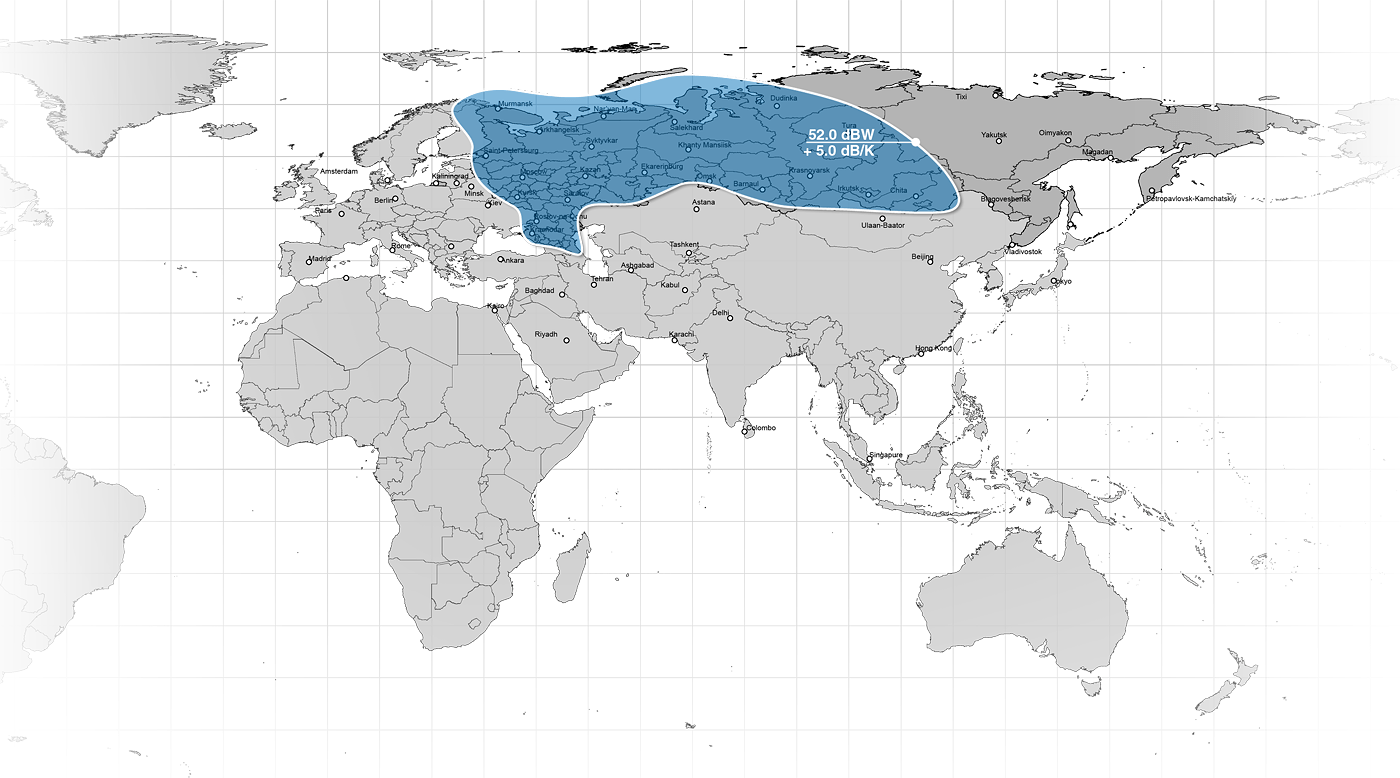
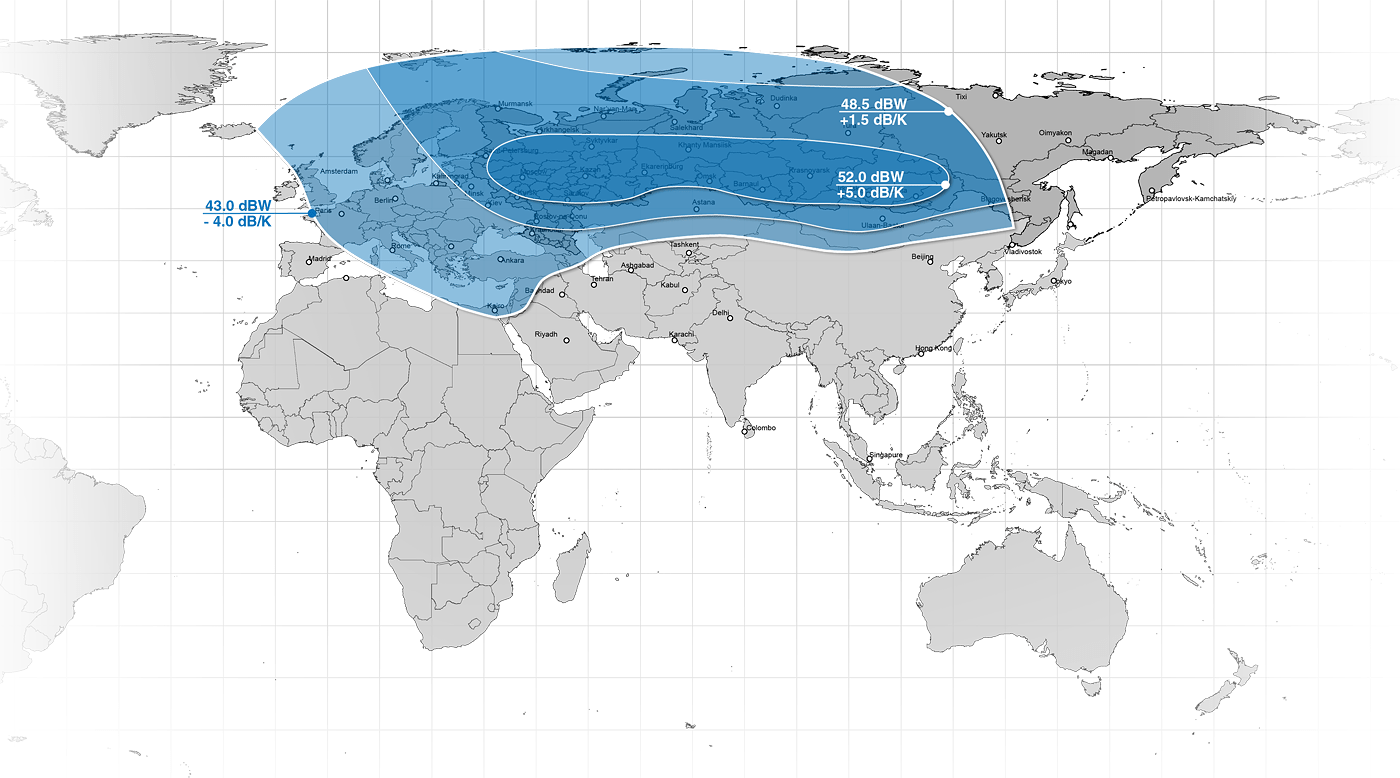
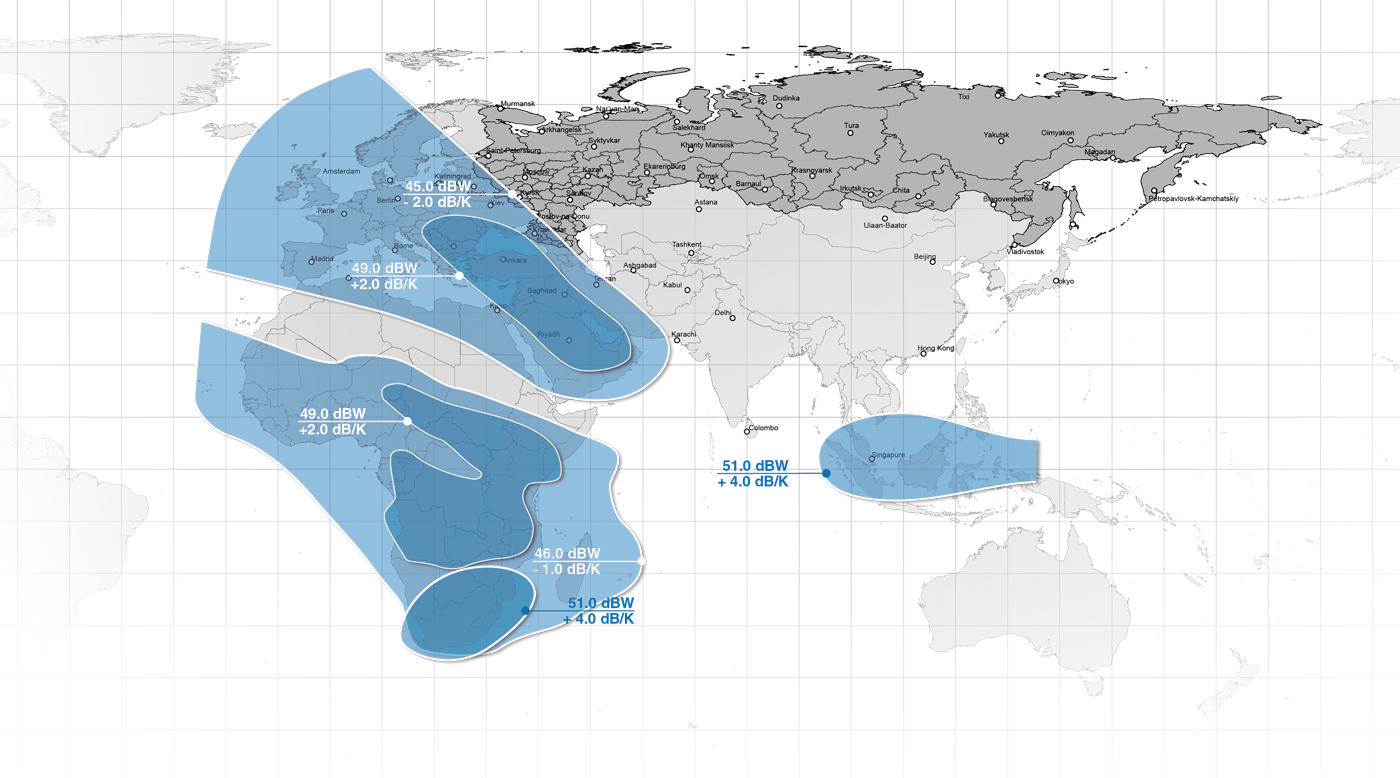
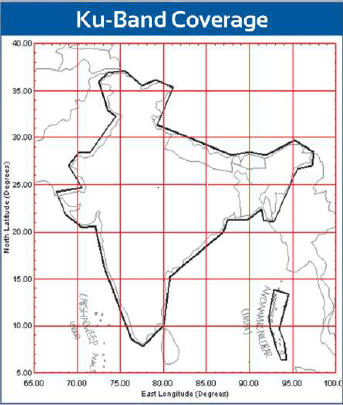
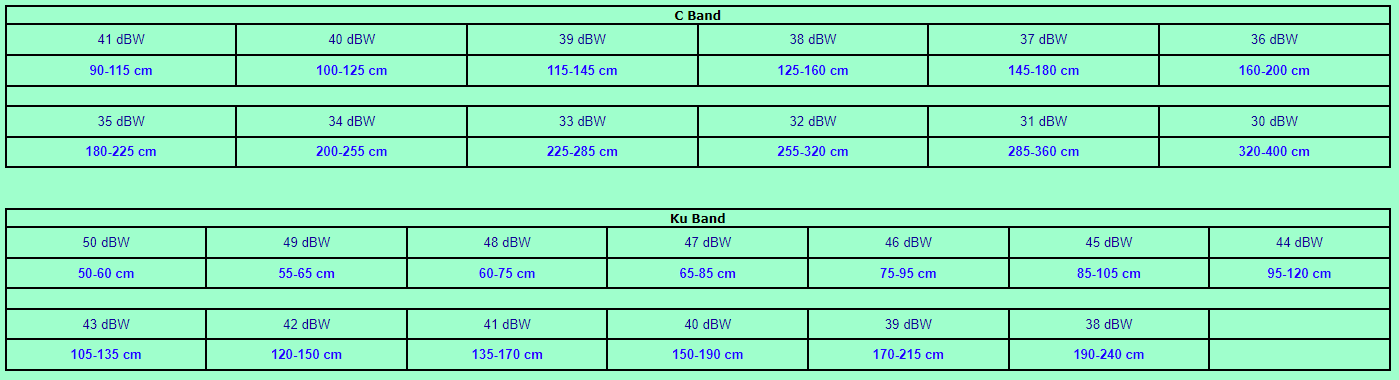
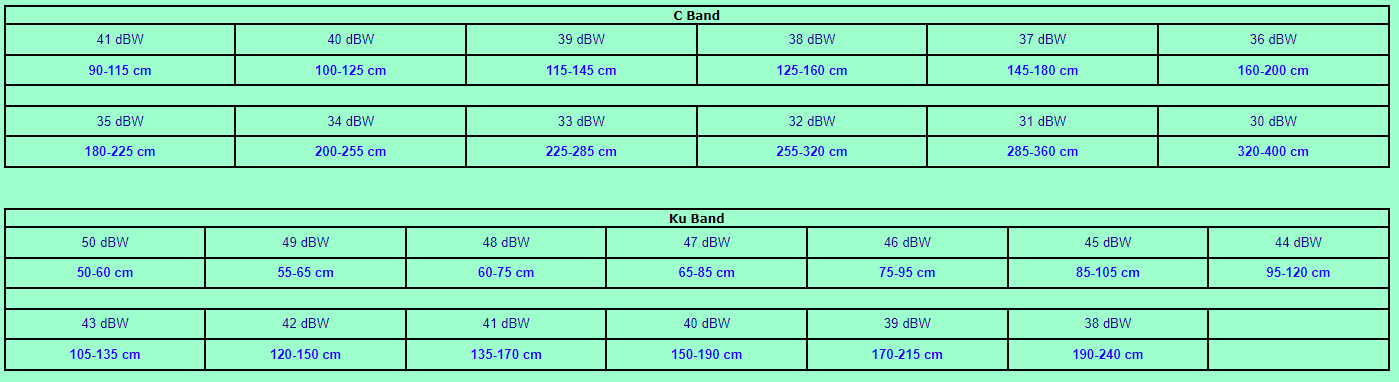
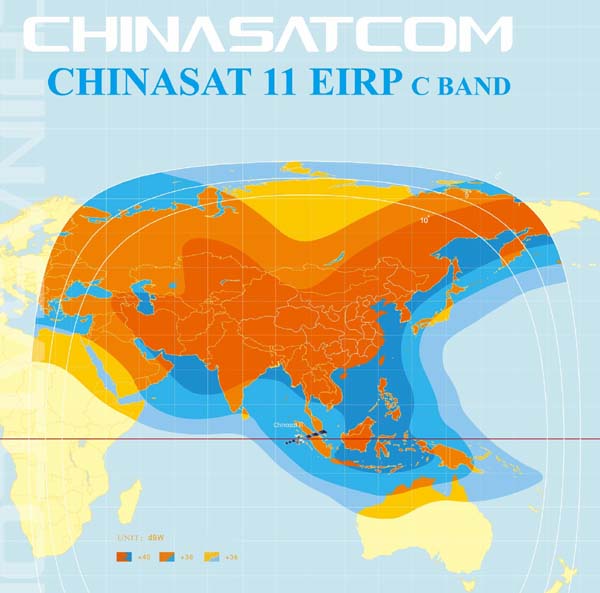
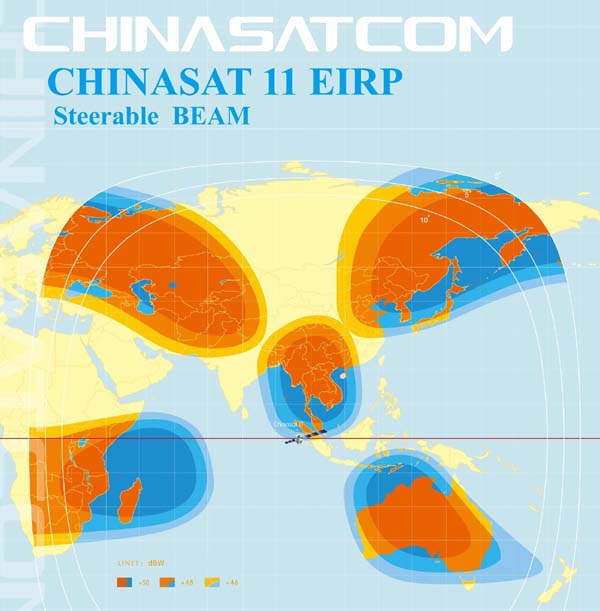
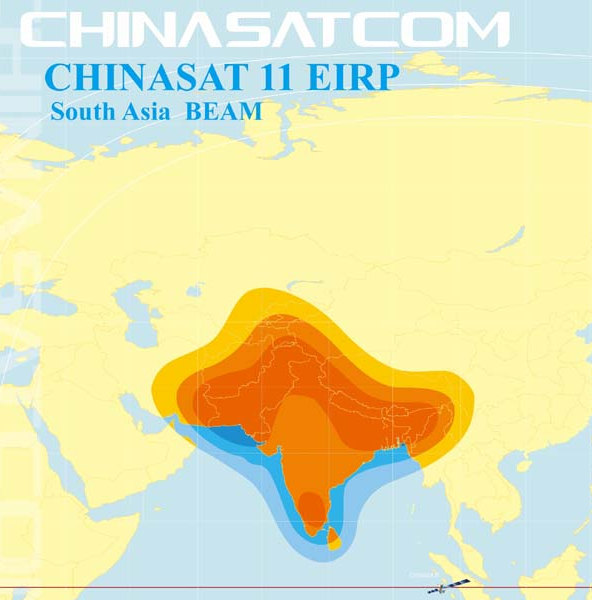
<!–IMG19–>Заходите на наш Телеграм-Канал @salesat общайтесь, задавайте вопросы и получайте самые свежие новости быстрее всех!
Так-же читайте транспондерные и спутниковые новости ВКонтакте

Ещё новости:
- Создатели фильма «Вызов» получили Государственную премию за искусство Госпремия «за выдающиеся достижения в области литературы…
- Канал с русскоязычной звуковой дорожкой «MyZen TV HD» ушёл из пакета Спутник "Eutelsat 16A" 16 E 11637 H…
- Космонавты на МКС провели обслуживание российской бегущей дорожки На Международной космической станции продолжается полет российских…


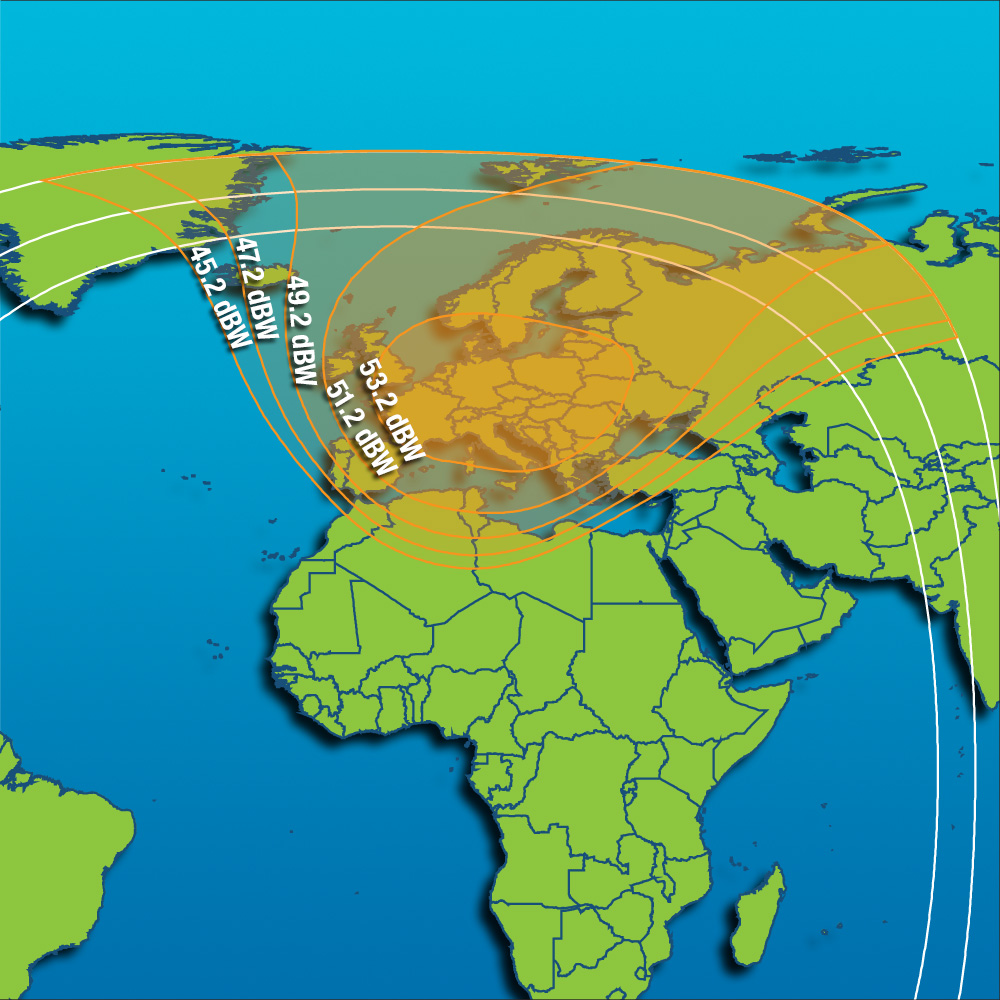
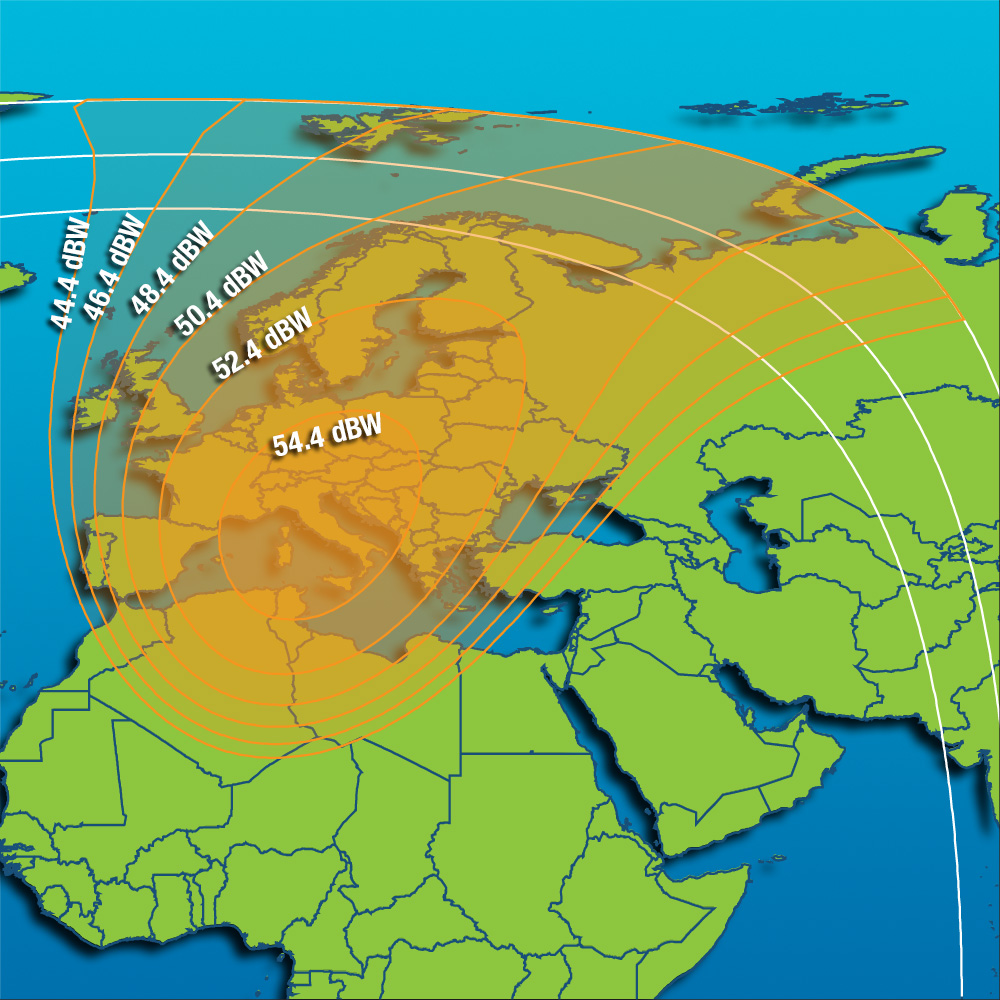
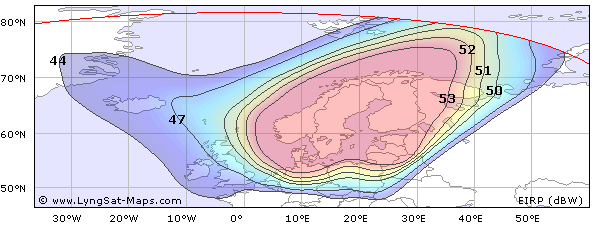
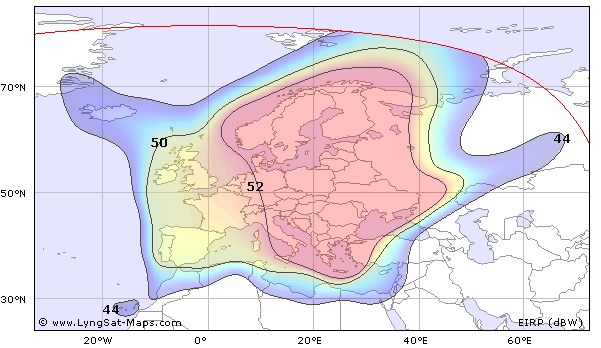
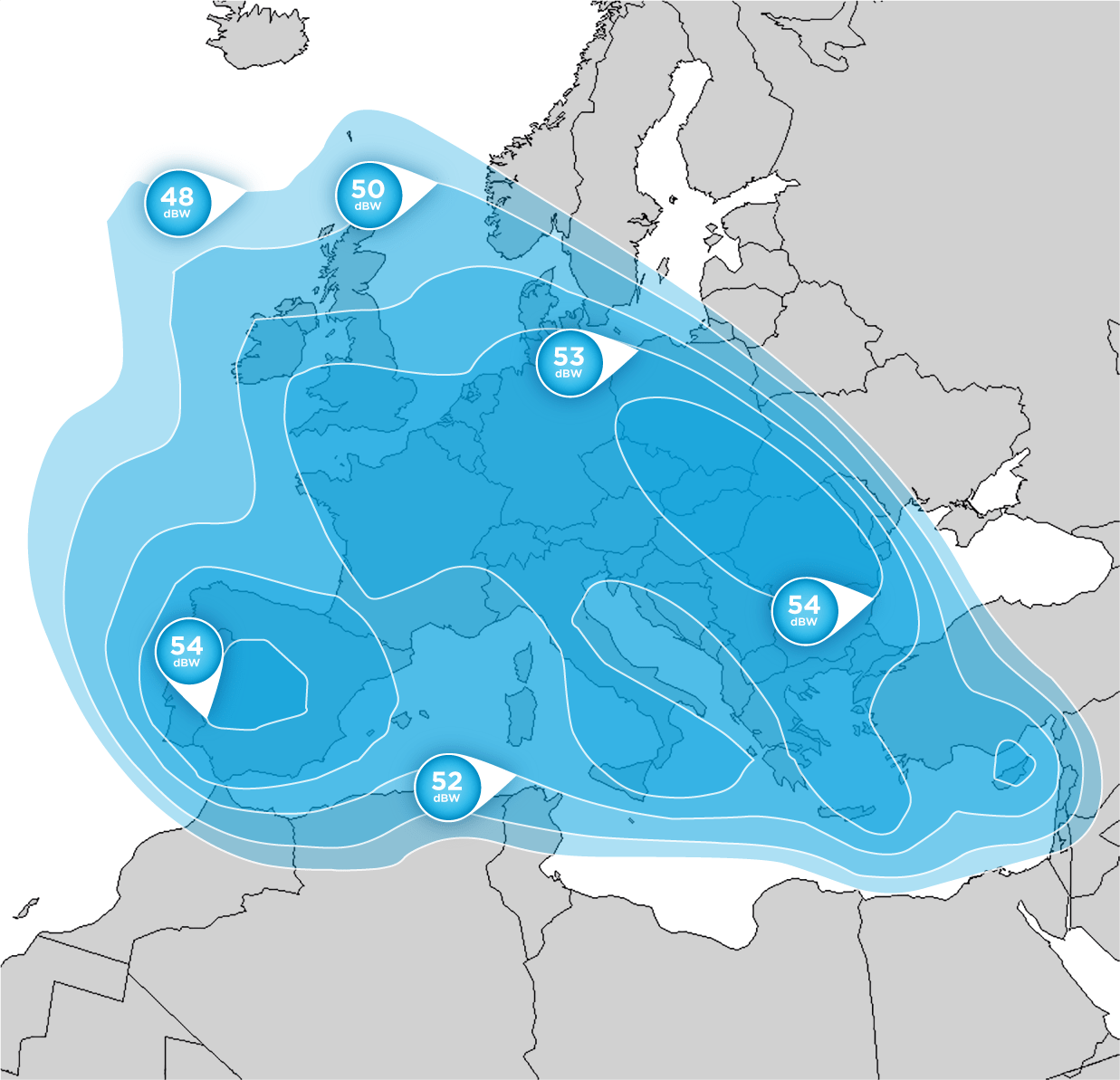
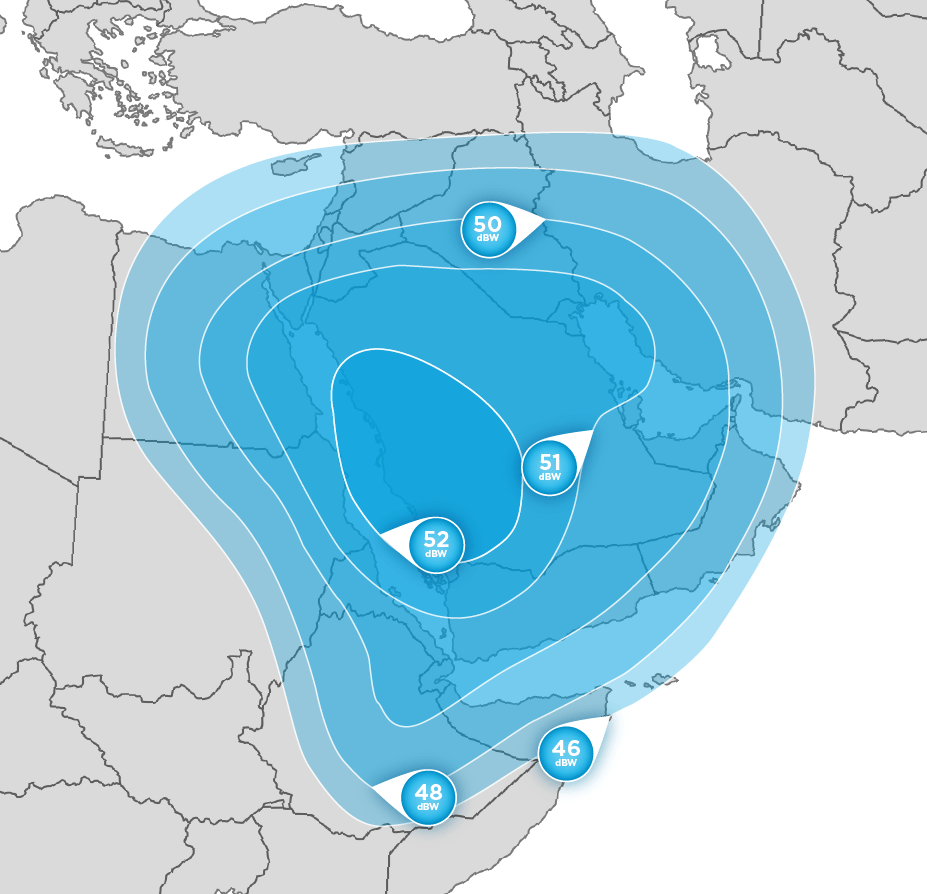
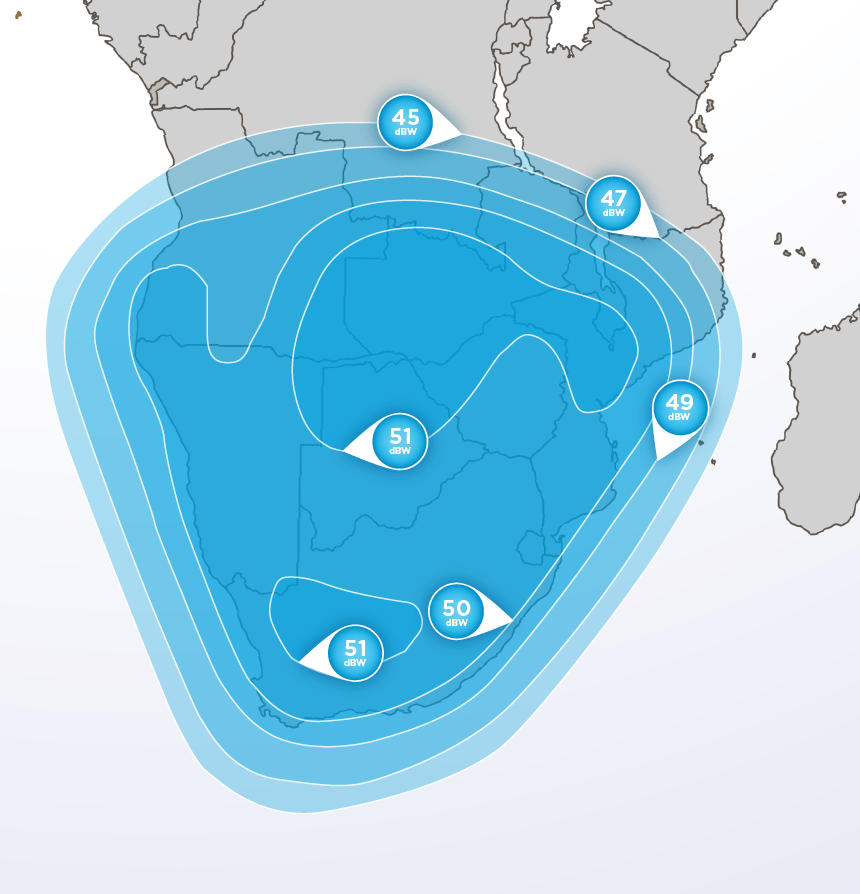
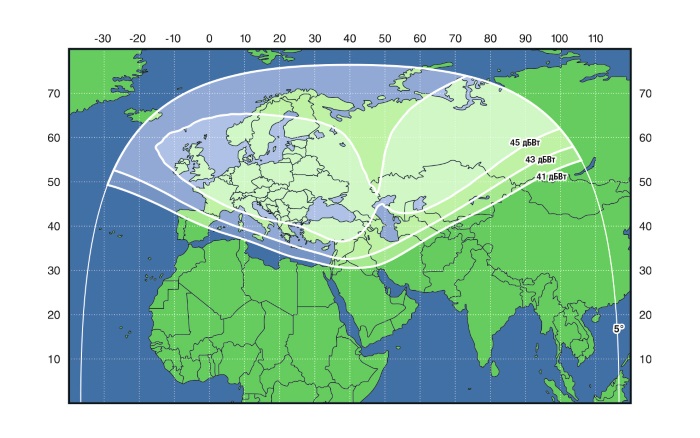

Свежие комментарии